In this article I'll describe the World Wide Web from a high level perspective, focusing on how a web page is request and delivered from a web server to a web browser. Then, I want to talk about web browsers, how they interpret the HTML you write, differences between browsers, what are standards and to paraphrase the old joke "if Standards are so great, why are there so many of them?" Finally, I'll talk about the thought process behind HTML5 and CSS3, why they were introduced and what they hope to achieve.
A Brief Technical Overview of the World Wide Web
The World Wide Web started out as a means for sharing scientific resources like research documentation between governmental and academic institutions. It took time for the technologies and practices to evolve beyond its original purpose.
From a technical perspective, the World Wide Web is comprised of several technologies ... first, it involves a simple markup (the Hyper-text Markup Language, or HTML) to both structure and format textual information. When first introduced its claim to fame was the hyperlink which allowed the publisher of a document to add a link to other research papers available from across the world, creating a virtual web of information (thus, the name). Second, one or more interlinked pages are published to a server that is connected to an open network which we know today as the Internet.
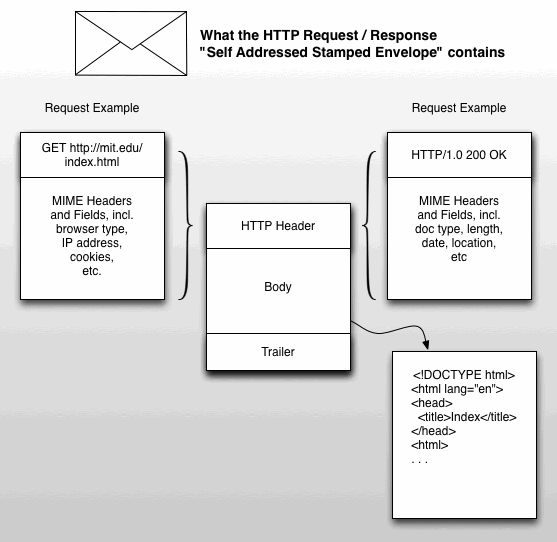
A protocol was devised that specialized in allowing a request/response-style communication between two computers. In other words, one user requests a document by typing an address for a document into a special program called a web browser, and the web browser packages up that request and sends it out into the network. The request takes the form of a specially formatted packet of data. You can think of this packet of information like a self-addressed stamped envelope -- containing both the address of the information requested and the address where that information should be sent back to. This specially formatted packet is known as Hyper-text Transfer Protocol, or rather, HTTP, and for simplicity's sake you can think of it merely as an electronic envelope. See Figure 1 for the types of information sent in the HTTP Request and HTTP Response messages.
Figure 1. The HTTP Request and Response messages contains important information that allows communication back and forth between the client and the server.
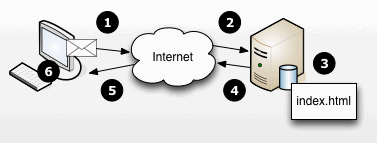
The HTTP request message is routed through a series of network wires and routers (i.e., devices that know how to forward HTTP messages closer to their destination) spanning the globe using (ideally) the shortest route possible until it arrives at its destination, the web server at the address the requestor typed into the web browser. The web server responds to the request by locating the requested document or resource (in the figure, the index.html file), packaging it up using the same HTTP style envelope, then sending the requested document back on to the network. The connection would only take a fraction of a second and once the computer served up the request, it would not retain any information about that request in its memory. See Figure 2 for a diagram of interactivity between the client and server computers.
Figure 2. (1) The HTTP Request is (2) routed across the internet to the (3) server which serves the (4) requested file back in the body of an HTTP Response message. (5) The HTTP Response is routed across the internet to the original requestor. (6) The requested file is parsed and displayed in the user's web browser.
Once the requested document is delivered through the network back to requestor, that document is loaded into the web browser. The browser parses through the HTML and decides how to render (or rather, display) its content and appearance on the computer screen.
What Are Domain Names?
The request that users type into web browsers originally looked something like this:
http://157.123.23.44/index.htm
Why the series of numbers? Each computer on this network was assigned an address, called an Internet Protocol Address, or IP Address. This was assigned through a lower-level protocol called Transmission Control Protocol / Internet Protocol, or rather, TCP/IP. It was the foundational technology that allowed requests to be routed to the appropriate server that contained a given resource, or rather, web page. However, because the IP address for a computer would change occasionally for a given computer or institution, they devised a system called the Domain Name System, or rather, the DNS, to turn a friendly name like:
mit.edu
... into the actual "location", like:
18.72.0.3
A system of top-level Domain Names was created ... .edu for educational institutions, .mil for Military, .gov for Government, .net for Network related resources, .org for Non-profit organizations, .com for Commercial organizations, etc. Later, other countries and a plethora of top-level domains were added and others for commercial and other interests.
The web browser will query databases of domain names and their associated IP Addresses and will translate the requests automatically for the user without his or her knowledge. Typically, each Internet Service Provider has a Domain Name System server that can be queried for resolving Domain Names into IP Addresses. The databases that contain this Domain Name information stay synchronized around the globe, although sometimes the synchronization process can take minutes or hours to complete.
The Purpose for Standards Groups
At every step of the way, one or more organizations were formed to help identify standards for these technologies comprised of experts and luminaries who were pushing these technologies forward. They would meet both virtually and in person to define and discuss the merits of adding new features to a given standard and would encourage organizations who were creating hardware and software to follow these standards so that products from different vendors could work together seamlessly. Perhaps one of the most influential and important standards body you will hear about is the W3C, or rather, the World Wide Web Consortium. They were one of the groups responsible for the latest version of HTML, version 5. Another is the WHATWG, or rather, the Web Hypertext Application Technology Working Group, which is comprised of a subset of the W3C and several additional experts and organizations that have a vested interest in the vitality of the World Wide Web. The background of HTML5, the previous versions of HTML, as well as the standards organizations involved is fascinating because you get a peek into both the process and the politics of these organizations.
Recap of the World Wide Web Technical Overview
From a purely technical perspective, you should now understand a few things:
First of all, hopefully you now have an answer to the question everyone first starting out asks: "why the heck did they make URLs so convoluted? Wouldn't it be easier to just type in 'microsoft' instead of 'http://www.microsoft.com'?" There's an evolution of technologies, and furthermore, it was never intended for use by the masses. At some point commercialized and individual access to the internet dwarfed the intended use, however the technologies created 30 years ago are still in play.
Second, hopefully you will begin see the purpose of things like http:// ... in which you are saying you want to access a specific channel of traffic, HTTP, or rather, World Wide Web traffic, as opposed to FTP (File Transfer Protocol) for working with large files, SMTP (Simple Mail Transfer Protocol) for sending email, and so on.
Third, hopefully you see the purpose of .com, .edu, .net and so on ... at least, you understand the original purpose, and you understand how those domain names are translated into the actual IP Addresses that are utilized by routers to move traffic around the internet to it's intended destination.
Fourth, hopefully you can see that the specifics of HTML - and all other standards - are decided on by a body of individuals who understand what is needed and propose and debate the merits of adding or removing parts of a given specification. You should also see the purpose for these standards - so that organizations creating hardware and software to support the World Wide Web can achieve a high degree of interoperability.
Fifth, hopefully you can see the role that each component plays in the exchange of documents and other resources ... the web browser is responsible for interacting with the end user who requests a document by typing in a web address or clicks on a hyperlink. It also packages up that request and begins the process of requesting the document from it's host, the computer called the web server. The message is packaged using the HTTP protocol, which you can think of as an electronic envelope geared towards stateless request / response style transmissions between two computers. Routers are special devices that know how to interpret the address encoded in electronic envelopes, or rather, the HTTP messages, and route them closer to their ultimate destination. A web server is merely a computer at a given web address that is listening for HTTP requests, and if the address is valid, returns the requested document or resource using the same HTTP message addressing as a response.
One Final Note About Our Overview
Let me add that (a) I distilled this down and over-simplified it to keep it simple at a high level. You could spend months or years learning more about any single component of what I just described in a few sentences, and (b) after 30 years of use and technological advancement, web development has gotten a LOT more sophisticated. And most pertinent to this series of lessons, web development techniques and technologies have become much more sophisticated. While most of the underpinnings are still in play, some of the technologies have been refined and expanded.
Take HTML for example. In early versions, HTML was called on to do "double-duty" ... it expressed both the structure of a document as well as its aesthetic layout. In other words, the same syntax defined both the fact that there would be fie paragraphs separated by a series of headings indicating the relationship of those paragraphs to each other, AS WELL AS the font types, colors and sizes, the border around the web page, the rounded corners and other adornments to make the web page attractive. While scientists and academicians may not be overly concerned about the aesthetics, at least not 30 years ago, now the World Wide Web is used for eCommerce, web applications that mimic desktop applications, gaming and more.
More recently, these two responsibilities - of structure and presentation - have been split in two ... HTML should define the structure of the document, and Cascading Style Sheets should control the presentation, or rather, the style or aesthetic qualities of a web page. We'll see how this separation of responsibilities plays out throughout this course.
How Web Browsers Parse HTML
One final topic I want to talk about that affects modern web development is the implementations of various web browsers. As you'll recall, once the requested web page has been returned, it will be parsed by a web browser then displayed on screen.
There are four major parsing and rendering engines that are popular today.
Trident, the web browser engine from Internet Explorer, is used by many applications on the Microsoft Windows platform, such as netSmart, Outlook Express, some versions of Microsoft Outlook, and the mini-browsers in Winamp and RealPlayer.
KDE's open-source KHTML engine is used in KDE's Konqueror web browser and was the basis for WebKit, the rendering engine in Apple's Safari and Google's Chrome web browsers.
Gecko, the Mozilla project's open-source web browser engine, is used by a variety of products derived from the Mozilla code base, including the Firefox web browser, the Thunderbird e-mail client, and SeaMonkey internet suite.
Opera Software's proprietary Presto engine is licensed to a number of other software vendors, and is used in Opera's own web browser.
They are *mostly* the same, in so much that a web page will look mostly the same regardless of which web browser it is loaded into. However it is the differences between them that most people discuss because it provides design challenges.
What do I mean when I use the terms "parse" and "render"?
The term "parse" refers to the process of breaking apart the HTML document to better "understand" the instructions coded there in. During this phase, other resources, like external CSS files or JavaScript files, or images, must be requested so that the browser can get a complete picture of the code it is responsible for ultimately rendering. After all those external resources are downloaded and analyzed, they are typically loaded into the computer's memory as a tree, or hierarchy, of software objects then passed to the rendering engine component of the browser - more about that in a moment. When I refer to these hierarchical software objects, I simply mean that some objects "own" or are parents to other objects ... a simple example might be that a paragraph is a parent to each sentence, which is a parent to each word. There might be other tags and graphical elements that the paragraph owns as well. This is simply part of the process of deciding what technique the browser will use to ultimately render the HTML to the screen.
Characteristics of HTML5 Web Pages
Each web page should declare which standard it has promised to adhere to. This is called a DOCTYPE, and it is the reason that we typed this:
<!DOCTYPE html>
... at the very top of our web page. This instruction told any web browser that may open it that it should be evaluated as an HTML5 document, as opposed to an HTML document of another version. Every instruction should adhere to the HTML5 specification (which we'll talk about in a moment). If it doesn't, the renderer may not know how to properly apply the rules of HTML5 to the document and must drop back into something called "quirks mode" where the browser will take a best guess on how to best render the web page. "Quirks mode" exists because there are plenty of poorly coded HTML page in the world and the web browser wants to try to the best of its ability to render something to the end user. If web browsers through up their hands and complained each time a web developer wrote bad code, the World Wide Web experience would be dreadful. Since writing HTML that doesn't validate against a standard can produce inconsistent results, web developers are strongly encouraged to take great care in the code they write. In fact, most tools that allow you to write HTML pages incorporate a validator to ensure the code you write validates against your chosen HTML specification. We'll use an HTML5 validator that's available on the internet for free in just a moment.
Once the document has been parsed, the browser can begin the rendering process. "Render" means that the code will be translated into visual elements on screen using algorithms and rules coded into the rendering engine, the components in the web browser responsible for this activity. The rendering engine will figure out how much screen space is available, and will begin to dole out the screen real estate equitably to lay out the various parts of the page onto the computer screen. There's much more to it than that, but again I'm just trying to speak at a very high level about what happens here.
And here is where things start to get messy, because I said all of that to say this: each rendering engine is written by different developers each determining how to satisfy the requirements of the specification in their code. Most of the time, your valid HTML5 code will look "close enough" on most browser vendor and versions. However, that's unfortunately not always the case and so it is important to set your expectations and give you a little heads up on how to deal with the inevitable situation where you want to use some new feature that is either supported differently in different browsers or is not supported at all in older browsers.
Let's start with the question if there's a standard in place, why do browser vendors implement functionality differently? Often this is a matter of interpretation of the specification. The specification details how something should work and provides some scenarios. From a technical perspective, there are situations not covered explicitly by the specification and vendors need to decide how THEY will handle it. In other cases, different vendors have different timeframes on when they plan on supporting the functionality. This has to do often with non-technical issues like budgets and resources and release schedules. For example, I saw a graphic comparing the number of features added to IE10 that were not in IE9. It was staggering, and strategically IE10 has a goal of supporting the release of Windows 8.
If you're not aware, you can build Metro-style Windows applications using HTML5, CSS3 and JavaScript via the WinRT API. Prior versions of IE9 did not have this requirement, and so the feature set it supported was decidedly smaller in preparation for a larger budget and team assigned to IE10.
Couple different interpretations of the specification with the fact that parts of the specification are not even complete, like I said in the first lesson, and you have a recipe for a divergence of implementations of the standards. Again, much of the standard works correctly.
So, what to do when you as a web developer want to make sure that your web page is rendered correctly in as many web browsers as possible? First of all, you need to become aware of those situations where implementations vary between the rendering engines. Testing your web pages in multiple browsers and on multiple devices will help identify those in your particular web pages, but over time, as you become more familiar with HTML and CSS you'll know where the potholes are. Secondly, you can take one of two approaches ... the first approach is called "Graceful Degradation" where you build your ideal web page to design at the latest version of a target web browser, then use CSS and JavaScript, images and emulation scripts that attempt to duplicate the features supported by the latest versions of one or more web browsers. Using this first technique, you are trying to get older browsers or current versions of other browsers to do things they are not capable of using copious sections of alternate HTML, CSS and JavaScript. You spend a lot of time wrestling with the site to get it as close as possible in older or less capable browsers.
Alternatively, you could take the "Progressive Enhancement" approach, meaning you start out by keeping the web page you're authoring as simple and straight forward as possible making sure the site looks as good as possible in baseline browsers ... in other words, you decide on a set of older web browsers as the baseline, make sure the web page looks good in those browsers, then add in features that are supported in newer browsers to enhance the web site. In this way you ensure that users with older browsers still have a good experience, you focus on writing good, solid HTML code, and for those who are running newer browsers you are adding features that will simply enhance their experience. Over time, you re-visit the web page's code, replacing those bits those older parts with those parts that were merely enhancements. People will eventually upgrade their browsers and as they do, your baseline can creep forward. This is an ongoing migration strategy. Most developers agree in principle that this is the right approach, even if the implementation can be tricky at times. You have to decide whether some of the things I'll demonstrate here are worth the price you'll pay in alienating potential users with older web browsers that don't yet support parts of HTML5 and CSS3. You should always be testing your work in multiple web browsers across many different versions to know exactly how your web page performs. And, do as I say, not as I do, because that is a time-consuming and therefore expensive process. Real professionals take this seriously and I would recommend you do so, too. You may see me cut corners at times -- do as I say, not as I do.
Conclusion
Hopefully you can see the issues surrounding HTML5 and CSS3 with regards to their support by various versions and vendors of web browsers and two different thought processes on how to incorporate HTML5 into your own work.